Cuju
An Open Source Project for Virtualization-Based Fault Tolerance
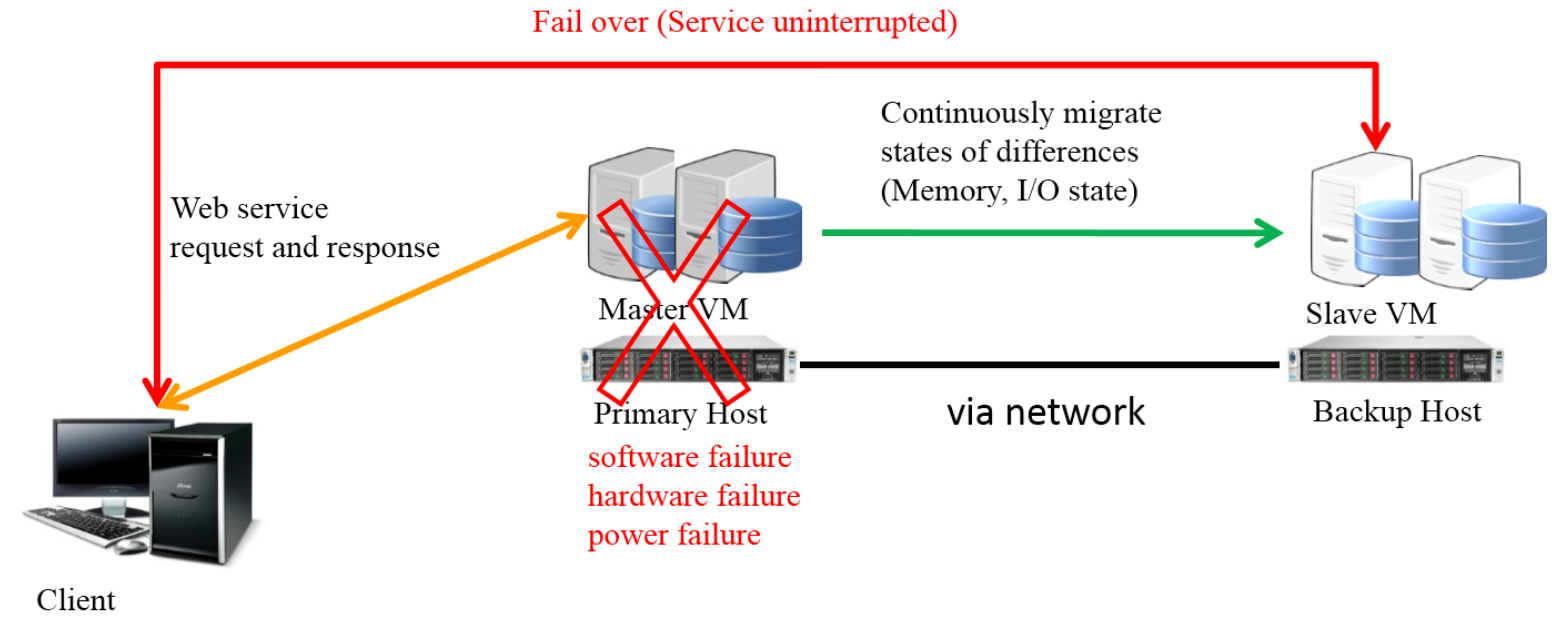
Virtualization technology has been widely adopted to enable elastic IT infrastructure, with improved manageability and increased service reliability. Especially, virtualization technology could provide a unique benefit to protect any legacy application systems from hardware failures. The reliability of virtual machines running on virtualized servers is not only threatened by hardware failures beneath the whole virtual infrastructure, but also nosy hypervisors that essentially support virtual machines cannot be trusted.
In this project, a virtualization- based fault tolerance mechanism using epoch-based (checkpoint- based) synchronization is proposed, named Cuju, and several performance optimization technologies are applied, including a non- stop/pipelined, continuously migration, dirty tracking for guest virtual memory/virtual device status, and eliminate data transfer between QEMU and KVM.
qCUDA
qCUDA is based on the virtio framework to provide the para-virtualized driver as “front-end”, and the device module as “back-end” for performing the interaction with API remoting and memory management. In our test environment, qCUDA can achieve above 95% of the bandwidth efficiency for most results by comparing with the native approach. In addition, by comparing with prior work, qCUDA has more flexibility and interposition that it can execute CUDA-compatible programs in the Linux and Windows VMs, respectively, on QEMU-KVM hypervisor for GPGPU virtualization.
System Components
The framework of qCUDA has three components, including qCUlibrary, qCUdriver and qCUdevice; the functions of these three components are defined as follows:
qCUlibrary (qcu-library) – The interposer library in VM (guest OS) provided CUDA runtime access, interface of memory allocation, qCUDA command (qCUcmd), and passing the qCUcmd to the qCUdriver.
qCUdriver (qcu-driver) – The front-end driver was responsible for the memory management, data movement, analyzing the qCUcmd from the qCUlibrary, and passing the qCUcmd by the control channel which is connected to the qCUdevice.
qCUdevice (qcu-device) – The virtual device as the back-end was responsible for receiving/sending the qCUcmd through the control channel; it depended on receiving the qCUcmd to active related operations in the host, including to register GPU binary, convert guest physical addresses (GPA) into host virtual addresses (HVA), and handle the CUDA runtime/driver APIs for accessing the GPU.
Paper
Yu-Shiang Lin, Chun-Yuan Lin, Che-Rung Lee, Yeh-Ching Chung, “qCUDA: GPGPU Virtualization for High Bandwidth Efficiency ”, CloudCom, 2019.
CUDA-clustalW
In computational biology, sequence alignment is of priority concern and many methods have been developed to solve sequence alignment-related problems for biological applicatons. ClustalW is a progressive multiple sequence alignment tool to align a set of sequences by repeatedly aligning pairs of sequences and previously generated alignments. Several algorithms or tools have been ported on GPUs with CUDA in computational biology, such as MUMmerGPU, CUDA-MEME, CUDA-BLASTP, and etc. Liu et al. proposed a tool MSA-CUDA to parallelize all three stages of ClustalW v2.0.9 processing pipeline by using inter-task parallelization. CUDA ClustalW v1.0 is a GPU version of ClustalW v2.0.11 which is implemented by using intra-task parallelization and Synchronous Diagonal Multiple Threads type. Several optimization methods were designed to improve the performance of CUDA ClustalW v1.0. From the experimental results, the CUDA ClustalW v1.0 can achieve about 22x speedups for 1000 sequences with length of 1532 in the distance matrix calculation step by comparing to ClustalW v2.0.11 on single-GPU. For the overall execution time, the CUDA ClustalW v1.0 can achieve about 33x speedups by comparing to ClustalW v2.0.11 on two-GPUs.
Version 1.0.0 (March 2013)
- Linux x86 64-bit
- CPU/GPU coprocess
- Support Multiple GPUs
- NVIDIA CUDA support
- Base on clustalW 2.0
Paper
- Che-Lun Hung, Yu-Shiang Lin, Chun-Yuan Lin, Yeh-Ching Chung, Yi-Fang Chung, “CUDA ClustalW: An efficient parallel algorithm for progressive multiple sequence alignment on Multi-GPUs”, CBAC(2015).
GOOS-SM
- Array operations are useful in a large number of important scientific codes, such as molecular dynamics, climate modeling, atmosphere, ocean sciences, and etc.
- To calculate the sparse matrix efficiently is a crucial issue (time) in many applications.
Motivation
- A data distribution scheme on the distributed memory multicomputers was the important research topic in the past.
- Data distribution scheme
- Send Followed Compress (SFC)
- Compress Followed Send (CFS)
- Encoding-Decoding (ED)
- Graphics Processing Unit (GPU) has become an attractive coprocessor for scientific computing due to its massive processing capability.
- There are several manuscripts about sparse matrix applications on the GPU have been published.
Goal
- Design the strategies for efficiently large amounts of compressing sparse matrices by using three data distribution schemes based on the GPU.
- The compressed sparse matrices in GPU can be queried for other matrix operations executing.
Parallelism scheme
- Intra-task parallelization
- Each task is assigned to one thread block and all dimBlock threads in the thread block cooperate to perform the task in parallel.
Conclusion
Optimal techniques using CUDA
Intra-task parallelization
Work-Efficient Parallel Scan
Avoiding Bank Conflicts
Coalescing
Cache Configurable
Using 12 GPUs, speedup can up to 55x
6000, 1024*1024 sparse matrix, total 23.4GB
CrackRSA
Cryptography is an important technique among various applications. In the telecommunication, cryptography is necessary when an untrusted medium is communicated in the network. RSA is a public-key cryptography algorithm to use a pair (N, E) as the public key and D as the private key. The N is the product of two large prime numbers p and q that are kept secret. It is very hard and no known polynomial time algorithms can be used to extract p and q from a large number N. There are many methods of factoring large numbers have been proposed. The advantages of computing power and memory bandwidth for modern GPUs have made porting applications on it become a very important issue. In this work, we proposed an efficient parallel RSA decryption algorithm for many-core GPUs with CUDA. The experimental results showed that the proposed GPU-based algorithm can achieve 1197.5x average speedup compared with the CPU-based algorithm, and within a reasonable time to find out the result of factoring large numbers.
Preliminary Concepts


Paper
- Yu-Shiang Lin, Chun-Yuan Lin, Der-Chyuan Lou, “Efficient Parallel RSA Decryption Algorithm for Many-core GPUs with CUDA”, ICTSM2012.
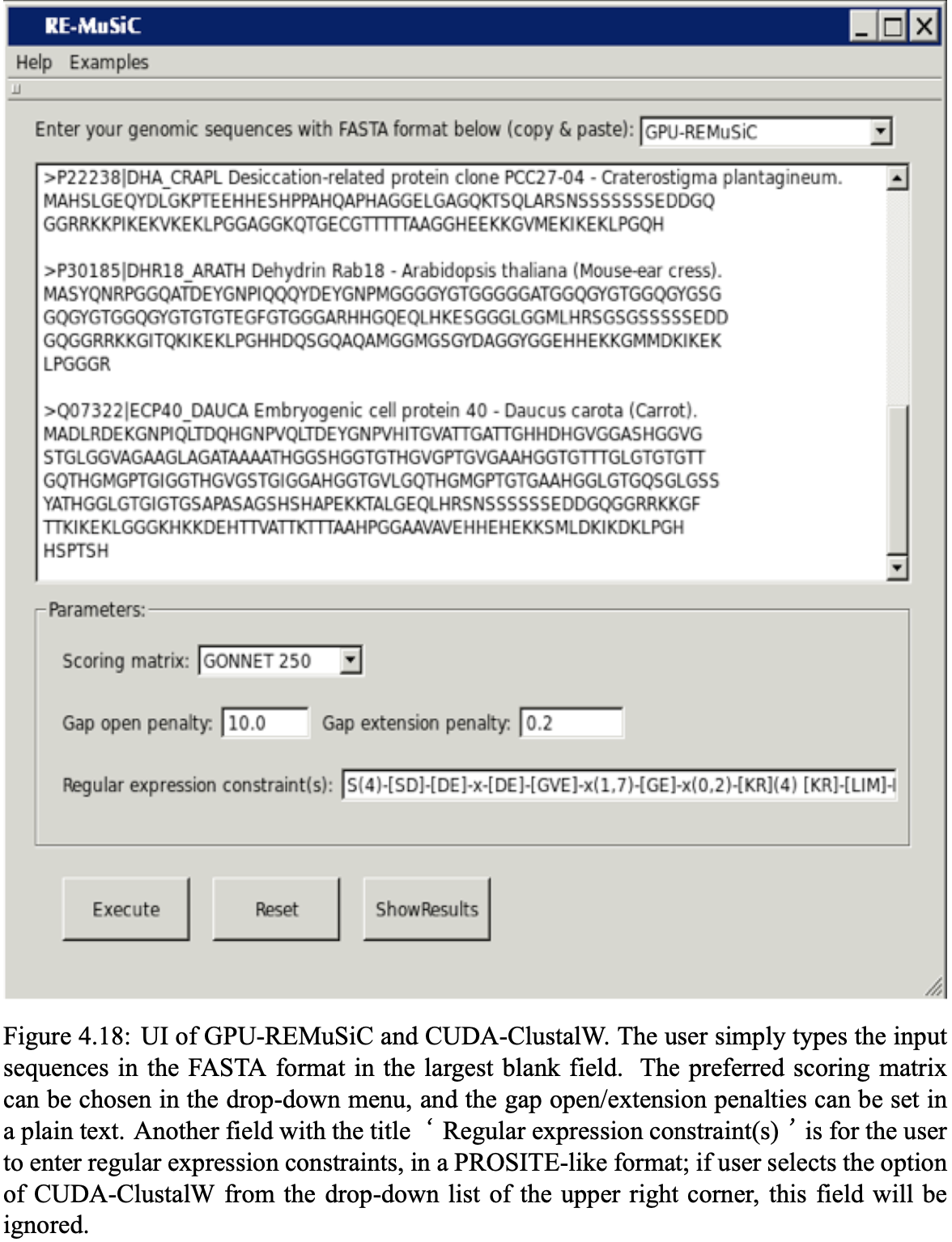
GPU-REMuSiC
Multiple sequence alignments with constrains has become an important problem in the computational biology. The concept of constrained sequence alignment is proposed to incorporate the biologist’s domain knowledge into sequence alignments such that the user-specified residues/segments are aligned together in the alignment results. Over the past decade, a series of constrained multiple sequence alignment tools were proposed in the literature. GPU-REMuSiC is a newest tool with the regular expression constrains and uses the graphics processing units (GPUs) with CUDA. GPU-REMuSiC can achieve 29× speedups for overall computation time by the experimental results.

Paper
- Che-Lun Hung, Yu-Shiang Lin, Chun-Yuan Lin, Yeh-Ching Chung, Yi-Fang Chung, “CUDA ClustalW: An efficient parallel algorithm for progressive multiple sequence alignment on Multi-GPUs”, CBAC(2015).
- Chun-Yuan Lin, Yu-Shiang Lin: Efficient parallel algorithm for multiple sequence alignments with regular expression constraints on graphics processing units. IJCSE 9(1/2): 11-20 (2014).
- Yu-Shiang Lin, Chun-Yuan Lin, Hsiao-Chieh Chi, Yeh-Ching Chung: Multiple Sequence Alignments with Regular Expression Constraints on a Cloud Service System. IJGHPC 5(3): 55-64 (2013).
- Yu-Shiang Lin, Chun-Yuan Lin, Yeh-Ching Chung, “GPU-Based Cloud Service for Multiple Sequence Alignments with Regular Expression Constrains”, CloudCom, 2012.
- Chun-Yuan Lin, Yu-Shiang Lin, Jiayi Zhou, and Chuan Yi Tang, “GPU-REMuSiC: Efficient Contrained Multiple Sequence Alignment Algorithm on Graphics Processing Units”, CTHPC, 2011.
- Yu-Shiang Lin, Chun-Yuan Lin, Sheng-Ta Li, Joy Lee, and Chuan Yi ang, “GPU-REMuSiC: the implementation of Constrain Multiple Sequence Alignment on Graphics Processing Units”, NVIDIA GPU Computing Seminar, 2010.